

Generative AI is having its moment in the sun — and it’s casting a menacing shadow over the creative industries while it does it.
The trouble is, too much of the conversation focuses on whether generative AI will replace creatives entirely (by generating images, copy and code from scratch). We think a better question to ask is: How could generative AI make creatives better?
Generative AI may one day be able to take on a fully-fledged designer — or it could fall flat on its originality-deficient face. But spotlighting the ways AI fails to totally replace creatives obscures how it could help them do better work, faster. So we’re shifting that gaze, through focused, practical testing with our generative AI 3-blog series.
—
Welcome back to Part 2 of our generative AI design shootout, where we’re putting 3 popular tools through their paces on real design challenges.
In our first test, we tasked Midjourney, Leonardo and Photoshop’s Firefly plugin beta with a common, quick design job: generating a mock-up for the cover of a texty whitepaper we’d use in a presentation.
The results were mixed. Midjourney gave us a fairly usable front cover, Firefly delivered a clean, blank canvas that would work well as a template, and Leonardo delivered a bit of a stinker.
Creating text was a universal issue across all of the results though, indicating that generative AI still hasn’t cracked that nut.
Overall the tools generated some usable results, but we concluded that designers might not save a huge amount of time using generative AI for that particular job. (Wondering WTF we’re talking about? Dig into the full prompts, results, analysis and summary in Part 1 here.)
And so: on to test 2.
Here, we’re upping the stakes with a more time-intensive job: generating entirely new variants of royalty-free images. Let’s dive in.
Test 2: Creating image variations from royalty-free stock images
Picture the scene: you’re trawling image libraries for the perfect stock photo, but nothing is hitting the mark. So you turn to generative AI to tweak an existing image from “almost right” to “bullseye”.
Here’s the original image we’ll be using from Unsplash:

Midjourney
The process for creating royalty-free image variants is relatively straightforward. First we uploaded our source photo and asked Midjourney to describe it. Then we used this generated description as the basis for prompts to generate new images. We found that this method delivered the most interesting and reliable results across our tests.

Here are the best four images Midjourney delivered:




Verdict:
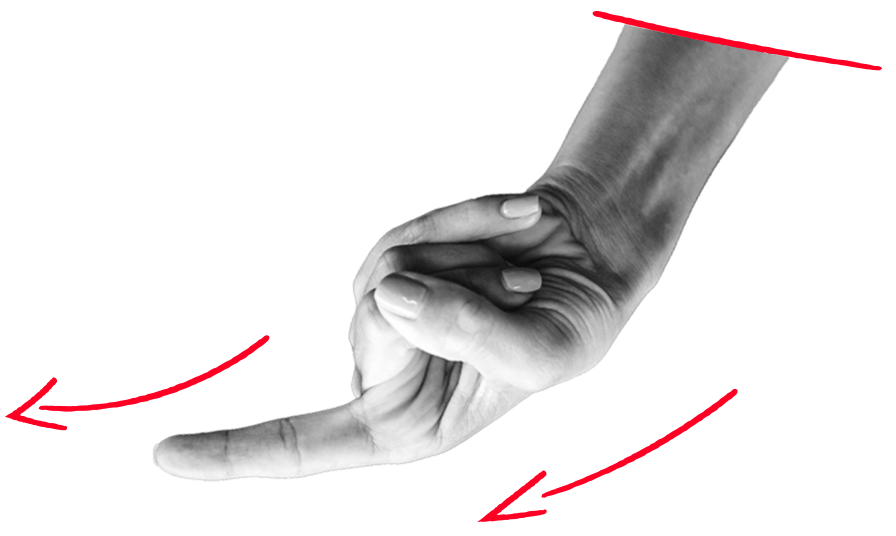
The results here are very usable. The images are mostly indistinguishable with those you’d find in a royalty-free image library. That said, generative AI famously struggles with hands — and while these variants are pretty passable at a glance, they’re not perfect.
Nevertheless, with Midjourney, it’s possible for us to create an unlimited number of variations of similar looking images. With more fine tuning of the prompt, we could potentially get even closer to the original if we needed to.
Overall, Midjourney did well here.
Leonardo
The process of creating image variations with Leonardo is very similar to Midjourney. You upload the original image, tweak the settings that influence visual style to get something close to what you’re looking for and include a prompt to go along with this.
We used the same prompt as the Midjourney test with a few small adjustments because Leonardo understands things in a slightly different way.
Prompt: a woman with a laptop, in a large office, blurred background, lots of background light from large windows, hispanicore, straight hair, smilecore, metalworking mastery, clean lines




Verdict: Them HANDS though. Leonardo clearly has a harder time with hands than Midjourney (the fourth image has an Insidious-level jumpscare when you see it). It can also struggle a little with perspective.
The changes to the model are worth digging into. Leonardo changed the model’s age, facial features and body type in a way that A) wasn’t specified by the prompt, and B) reveals the problematic biases within generative AI training data.
Leonardo independently veered into a more glamourized interpretation of the prompt. If we extrapolate this use case out, any company that regularly uses Leonardo to develop stock image variations could unintentionally compromise the diversity and representation within its output.
One supplementary point: Leonardo required a lot of experimentation with a vast array of settings to get to these results. So users will need to have a better mastery of prompt language and tweaking in order to use this VS the others.
Photoshop Beta using Firefly AI
Photoshop Beta places more limitations on creating image variations. In this test, we were only able to use it to change the background of the original image — not the model.




The verdict: Impressive stuff — these images need a certain degree of cleaning up, but they have seamlessly transported the model into a number of new locations very believably.
Test 2 summary:
Our second challenge delivered a substantially more interesting and valuable set of results compared to our first — notable when considering that this was deemed to be a more difficult/time-intensive job.
Midjourney is still killing it on the creativity front, with imagery not far off the level of quality you’d find on a stock image site. If there’s an image that you need to make a change to, it seems like it could deliver quite a good result quite fast.
But the Photoshop Firefly Beta is really stepping up its game with the level of control you have over the details of an image. Moving the model in the image into different scenarios can very easily look ‘off’, whether it’s perspective, lighting or small differences between the subject and the setting. The results generated do need some small tweaks, but again the images are impressively realized.
Once again, Leonardo did deliver in this test, but with substantial (and unrequested) changes to the model (plus the issues with hands and background perspective) it trails for a second test running. You’d need close oversight over the results which makes it less useful than Firefly Beta or MidJourney.
As ever, it’s important to note that this is just a singular test; you would certainly see different results for different images and approaches to their customization. But we have seen generative AI’s potential here, turning a relatively complex job around in a matter of seconds.
Next time:
We look at generative AI from a completely different creative angle in our third and final test: using descriptive prompts to generate some early landing page design ideas that a designer could take forward. See you for the culmination of the series.

Enjoyed this article?
Take part in the discussion




Comments
There are no comments yet for this post. Why not be the first?